How to start with Kafka basics and use it in Kotlin

In my last post, I finished my series about DynamoDB, and today it is the time for starting with the next topic that I divide in multiple posts, this time talking about Apache Kafka (in the following only named Kafka). I started using Kafka in more depth in the same project as DynamoDB. So I would also like to share what I have learned during this time. I only cover topics that I touched until now and there is no claim for completeness.
Introduction
Before diving into code, I want to start to give an overview about Kafka. It is important to have a high-level overview about the general parts of Kafka before starting to use it. Kafka is an open-source, distributed event streaming platform optimized for high-throughput and fault-tolerant data processing. It was originally developed by LinkedIn and is now maintained by the Apache Software Foundation, Kafka has become foundational for modern data architectures due to its ability to handle vast volumes of real-time data. It serves as the backbone for applications requiring a reliable, scalable, and durable system for managing data flows between distributed systems.
Core Concepts of Kafka
At its core, Kafka operates as a distributed "commit log" that records event streams in a durable, append-only sequence. Kafka’s architecture revolves around several key concepts:
-
Topics: Kafka organizes messages into categories called "topics." Each topic represents a specific data stream, such as user activity logs or transaction records. Topics allow Kafka to decouple data producers from data consumers, enabling a flexible and efficient publish-subscribe pattern.
-
Producers and Consumers: Producers are services that write data to Kafka topics, while consumers subscribe to topics and retrieve data. Kafka allows multiple producers to write to the same topic and multiple consumers to read from it, which makes Kafka highly adaptable to various data use cases.
-
Partitions: Each topic is divided into partitions, which are ordered, immutable sequences of records. Partitions are the primary mechanism for Kafka's scalability, as they enable parallel processing. Each partition can reside on a different server (or broker), allowing Kafka to handle large data volumes by distributing the workload across a cluster.
-
Brokers and Clusters: Kafka runs as a cluster of servers, each server referred to as a broker. Brokers store data across partitions and replicate it to ensure durability. A Kafka cluster is fault-tolerant; if a broker fails, another broker takes over, ensuring data availability and reliability (as long as there is more than one broker available).
How Kafka Works
Kafka’s underlying architecture is built to handle event-driven data pipelines and stream processing systems where real-time data flow is essential. It works on a publish-subscribe model:
Producers send records to a specified topic within Kafka. They push data into Kafka, which assigns it to a partition based on a configurable key. Consumers read records from topics and can keep track of which messages they’ve processed. Kafka maintains the offset for each message, allowing consumers to replay or continue from where they left off, making it suitable for scenarios that require data persistence and message reprocessing. A distinguishing feature of Kafka is its ability to retain messages for a specified period, even after they’ve been consumed. This makes Kafka not just a messaging queue but also a storage layer where data can be retained for hours, days, or longer. Consumers can process these retained messages anytime, supporting various use cases from stream processing to log analysis and beyond.
Why Use Kafka?
Kafka's architecture is designed to be fault-tolerant and scalable, making it an ideal choice for high-throughput, distributed data applications. Here are some key advantages that Kafka offers:
-
Scalability: Kafka can handle millions of messages per second through partitioning. Adding more consumers and partitions can horizontally scale the system.
-
Durability and Reliability: Kafka replicates data across multiple brokers, so if one broker fails, data remains accessible. Kafka guarantees message delivery, ensuring no data loss, which is critical for financial or transactional data.
-
Low Latency: Kafka provides high throughput and low latency for both publishing and consuming messages, suitable for time-sensitive applications like real-time analytics.
-
Data Decoupling: Kafka decouples data sources (producers) from data sinks (consumers), allowing developers to build resilient microservices architectures where each service can independently produce or consume data streams.
Key Use Cases
Kafka's versatility makes it suitable for a wide range of applications, including:
-
Real-time Analytics: Kafka’s event-streaming capabilities allow businesses to perform analytics on data as it flows in, providing insights in real-time.
-
Data Pipelines: Kafka can act as a robust data pipeline, delivering data from sources (like databases, or applications) to other systems or data lakes.
-
Log Aggregation: Kafka efficiently collects and distributes log or event data from multiple sources for monitoring, troubleshooting, and alerting.
-
Event Sourcing and Stream Processing: Kafka supports complex stream processing frameworks (e.g., Kafka Streams, Apache Flink) to allow transformations, aggregations, and complex workflows over streaming data.
That’s for now enough of introduction and theory, let’s get my hands dirty and write some code…
Implementation
When starting with Kafka there are multiple options possible to get a runnable cluster that I can interact with:
-
I can download the binaries on the project website and run it on my local machine.
-
I can use the docker image (either the official one or one of the other available ones, e.g., of Confluent or Bitnami).
-
I can use the Conduktor cloud solution providing a Kafka cluster playground.
In my case, I use a docker-compose.yml file for configuring a Kafka cluster together with a UI that helps in the beginning to visualize what is happening and interact with Kafka easily. As the docker image, I use the one provided by Bitnami.
services:
kafka:
image: bitnami/kafka:3.7.1
container_name: kafka
hostname: kafka
command:
- 'sh'
- '-c'
- '/opt/bitnami/scripts/kafka/setup.sh && kafka-storage.sh format --config "$${KAFKA_CONF_FILE}" --cluster-id "lkorDA4qT6W1K_dk0LHvtg" --ignore-formatted && /opt/bitnami/scripts/kafka/run.sh' # Kraft specific initialise
environment:
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_KRAFT_CLUSTER_ID=lkorDA4qT6W1K_dk0LHvtg
- KAFKA_CFG_NODE_ID=1
- KAFKA_CFG_BROKER_ID=1
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@127.0.0.1:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,INTERNAL:PLAINTEXT
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LOG_DIRS=/tmp/logs
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_HOSTNAME=docker.for.mac.localhost
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,INTERNAL://:9094
# End Kraft Specific Setup
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092,INTERNAL://kafka:9094
ports:
- "9092:9092"
volumes:
- kafka_data:/bitnami
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "8080:8080"
restart: "always"
environment:
KAFKA_CLUSTERS_0_NAME: "MyFirstKafkaCluster"
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9094
KAFKA_BROKERCONNECT: kafka:9094
DYNAMIC_CONFIG_ENABLED: 'true'
volumes:
- kafkaUi_data:/etc/kafkaui
depends_on:
- kafka
volumes:
kafka_data:
driver: local
kafkaUi_data:
driver: localThe state of the Kafka cluster is persisted locally using a volume.
Starting both docker container and opening http://localhost:8080 shows me the below overview.
This is enough to start the practical introduction of using Kafka in my application. I use a plain Kotlin Gradle application; there is no additional framework necessary to show the basics. Also, the focus in the sample code is on explaining how producing and consuming messages with Kafka is working, not providing a production ready solution. In a follow-up post, I will integrate Kafka in a SpringBoot application and show how a real-world implementation can look like.
Let’s start with the producer part first.
Producer
To connect to the previous started Kafka cluster, I need to add a dependency to my application.
dependencies {
implementation("org.apache.kafka:kafka-clients:3.8.1")
}The next step is to configure the Kafka producer, setting properties like the Kafka server address and serialization format for the key and value of each message.
import org.apache.kafka.clients.producer.KafkaProducer
import org.apache.kafka.clients.producer.ProducerConfig
import org.apache.kafka.common.serialization.StringSerializer
import java.util.Properties
fun createProducer(): KafkaProducer<String, String> {
val props = Properties().apply {
put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092")
put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer::class.java.name)
put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer::class.java.name)
}
return KafkaProducer(props)
}In this configuration:
-
BOOTSTRAP_SERVERS_CONFIGspecifies the Kafka broker’s address. -
KEY_SERIALIZER_CLASS_CONFIGandVALUE_SERIALIZER_CLASS_CONFIGdefine how keys and values are serialized. Here I useStringSerializerfor both, but other types (e.g., JSON) are possible depending on the needs. For now, I want to keep things simple.
Once I’ve configured the producer, I can start sending messages to a topic. In this example, I’ll send a simple message to a specified topic.
import org.apache.kafka.clients.producer.ProducerRecord
import java.util.UUID
fun main() {
createProducer().use { producer ->
val topic = "my-first-topic"
val key = UUID.randomUUID().toString()
val value = "Hello, Kafka!"
try {
val record = ProducerRecord(topic, key, value)
val metadata = producer.send(record).get() // Synchronous send
println("Message sent to topic ${metadata.topic()} with offset ${metadata.offset()}")
} catch (e: Exception) {
println("Sending message failed because of: ${e.message}")
}
}
}In this example:
-
Instead of closing the producer in a
finallyblock, I use Kotlinsuse- extension function to close the resource. -
I create a
ProducerRecord, which includes the topic, key, and value. -
The
send()- method is used to send the message to Kafka. By calling.get(), I’m sending the message synchronously, waiting for the Kafka broker to acknowledge the message before proceeding.
Running the main - function automatically creates the my-first-topic topic in the Kafka cluster using the default configuration. This only works if the corresponding setting is activated (see documentation)
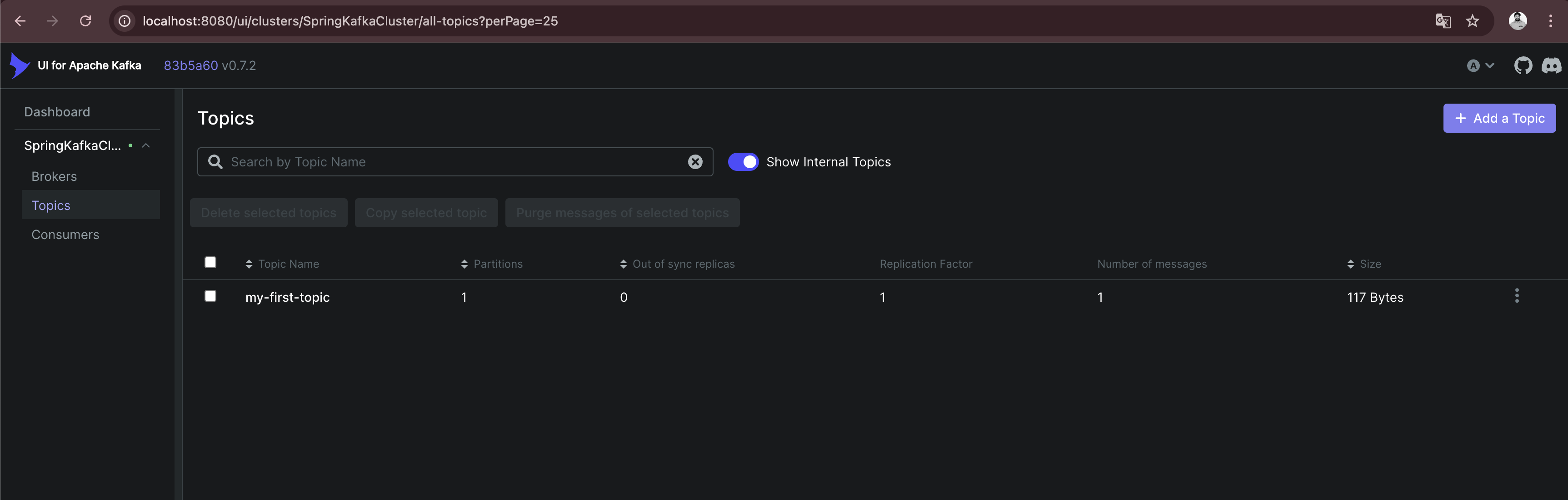
When I open the topic details, I can see that the message I just sent is available with the specified key and value. Also, the offset 0 is set together with a timestamp.
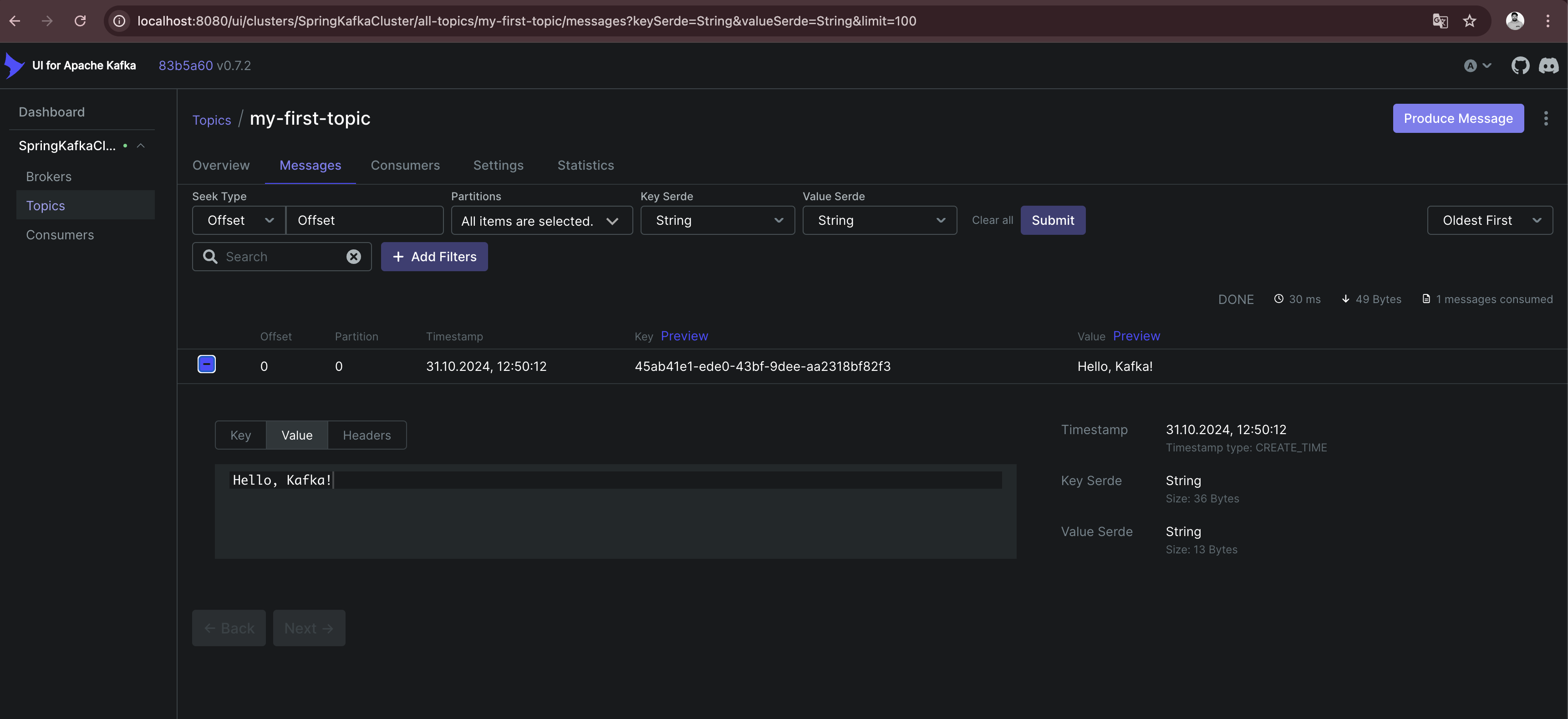
This was it, I successfully sent my first message to Kafka (even currently nobody consumes the messages).
In the next step, I want to send multiple messages and also instead of using a blocking call, which makes it necessary to catch a potential exception and not allows to suspend the processing, I use a callback.
suspend fun produceMessagesInLoop(producer: KafkaProducer<String, String>, topic: String) {
for (i in 1..10) {
val key = "key-$i"
val value = "message-$i"
sendAsyncMessage(producer, topic, key, value)
}
producer.flush()
}
suspend fun sendAsyncMessage(
producer: KafkaProducer<String, String>,
topic: String,
key: String,
value: String
) {
val record = ProducerRecord(topic, key, value)
suspendCoroutine { continuation ->
producer.send(record) { metadata, exception ->
if (exception != null) {
continuation.resumeWithException(exception)
} else {
println("Message sent to topic ${metadata.topic()} with offset ${metadata.offset()}")
continuation.resume(metadata)
}
}
}
}In this example:
-
I use the
send()- function with a callback and depending if an exception is returned or the message is successfully sent, callresumeWithException()on the continuation orresume(). This removes the synchronous call to Kafka.
The functionality creates 10 additional messages on the topic. When I look at the message overview in the topic, I can see that the messages have an increasing offset. The messages keep the order in which they are sent to Kafka. This works across all messages because currently I’m only using a single partition for all messages for this specific topic.
To see how messages are sent in case there are multiple partitions available, I create a new topic my-second-topic using the Kafka - UI:
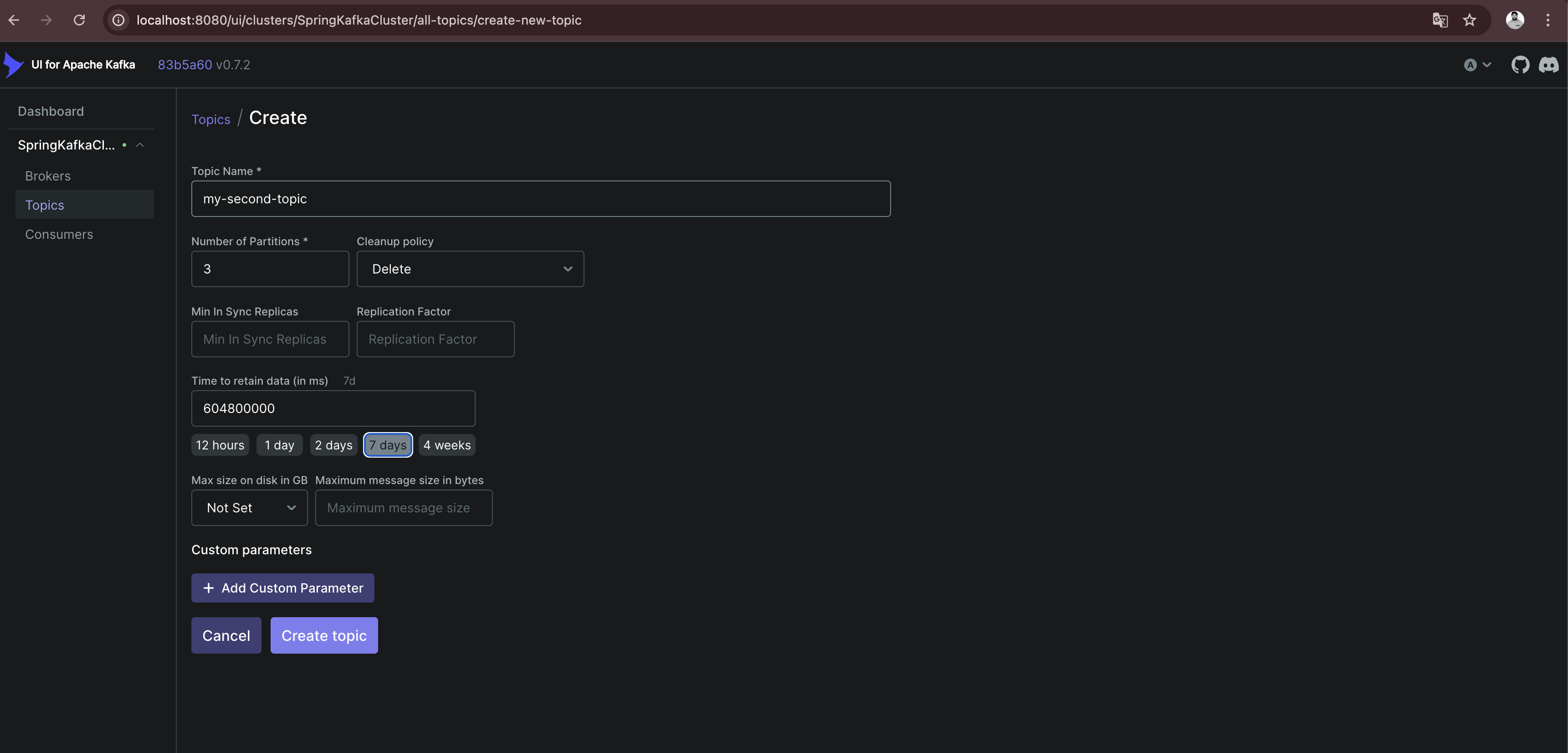
Showing the distribution between all available partitions (in the above case 3), makes it necessary to use a more random value for the key, because Kafka is distributing messages depending on the result of a hashing of the key.
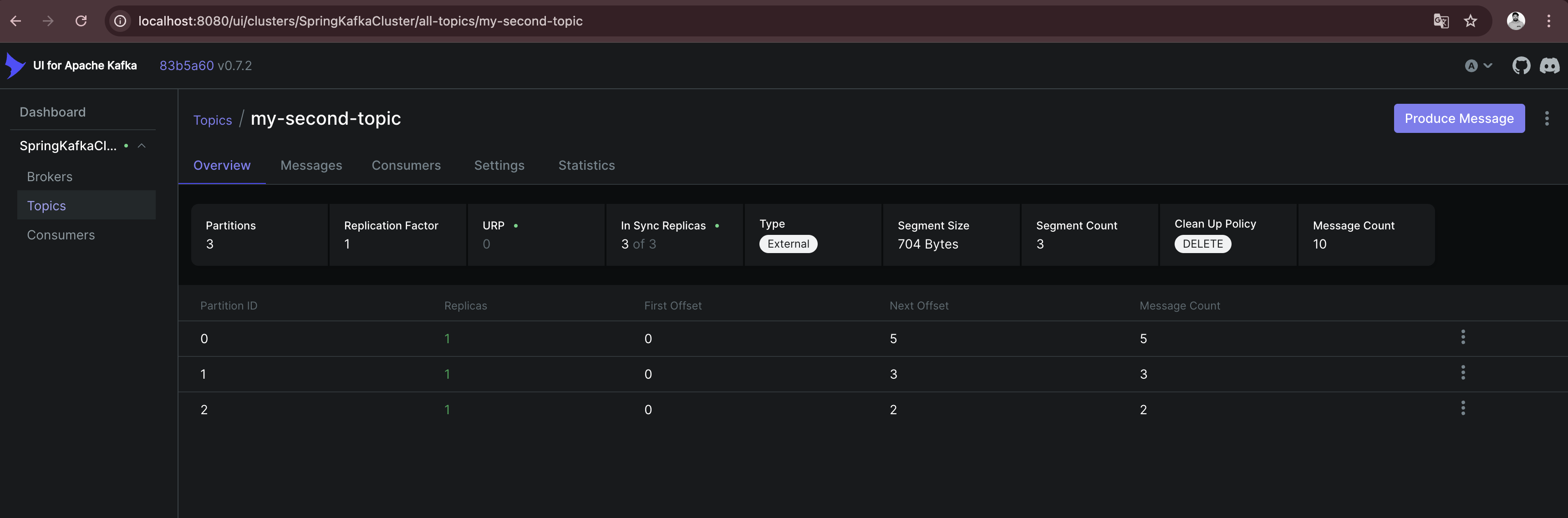
As I can see, there are messages in all partitions available. It is important to know, that the order of the messages is only guaranteed per partition, not across all partitions. Messages with the same key are always stored on the same partition, so if order matters caring about the key is important.
Kafka not only allows sending from one producer to the same topic but also from multiple.
suspend fun produceMessagesInLoop(producerName: String, producer: KafkaProducer<String, String>, topic: String) {
for (i in 1..10) {
delay(Random.nextLong(1000))
val key = UUID.randomUUID().toString()
val value = "$producerName-message-$i"
sendAsyncMessage(producer, topic, key, value)
}
producer.flush()
}
fun main(): Unit = runBlocking {
val topic = "my-third-topic"
launch {
createProducer().use { producer1 ->
produceMessagesInLoop("producer1", producer1, topic)
producer1.close()
}
}
launch {
createProducer().use { producer2 ->
produceMessagesInLoop("producer2", producer2, topic)
producer2.close()
}
}
}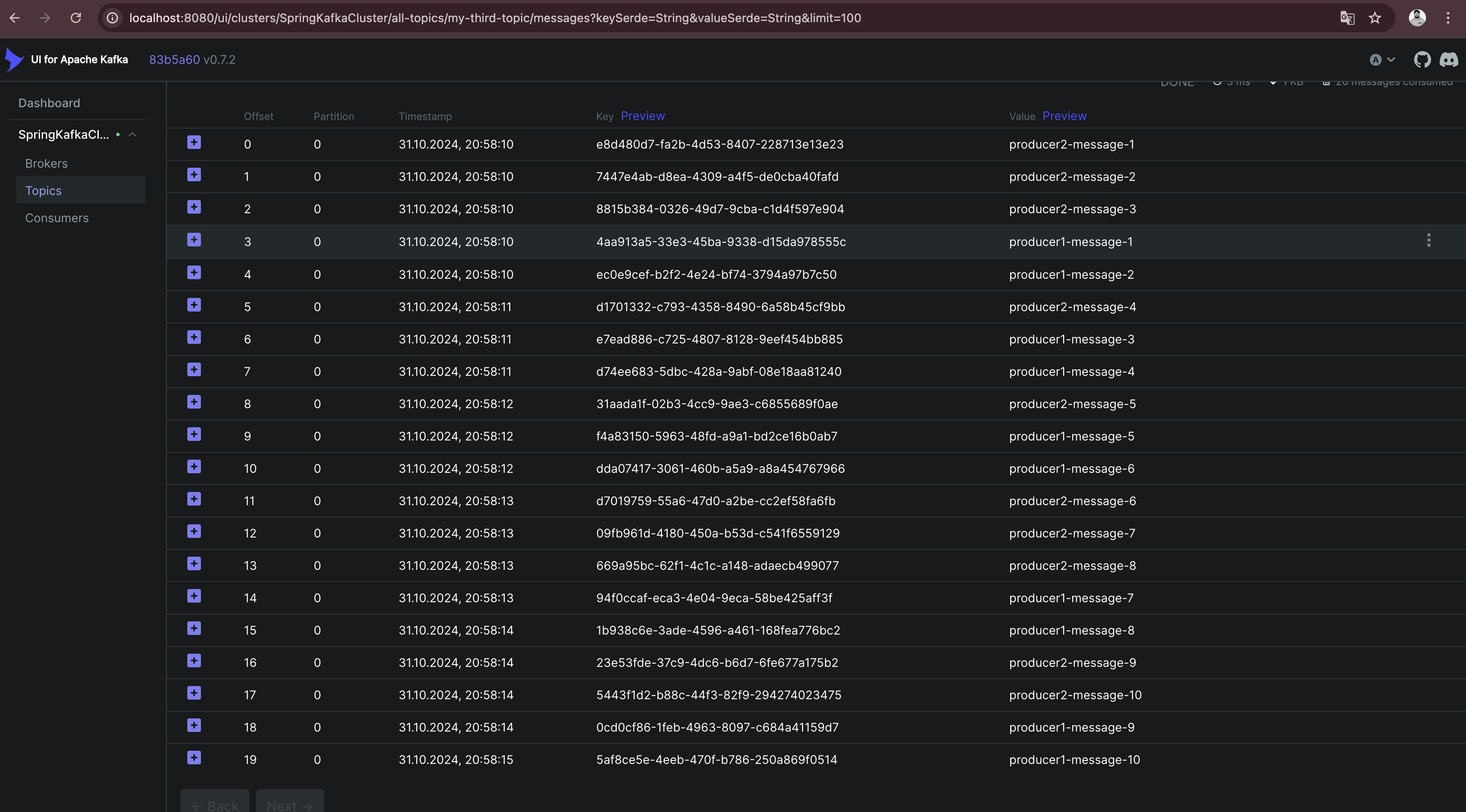
I add a random delay between the processing of each message so that the time in which a producer is able to send the next message varies and the result is more expressive.
Kafka producers allow fine-tuning for retries and acknowledgment behavior. Here are some commonly used configurations:
val props = Properties().apply {
put(ProducerConfig.ACKS_CONFIG, "all") // Wait for acknowledgment from all brokers
put(ProducerConfig.RETRIES_CONFIG, 3) // Retry up to 3 times on failure
put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 100) // 100 ms backoff between retries
put(ProducerConfig.LINGER_MS_CONFIG, 5) // Wait up to 5 ms to batch records together
put(ProducerConfig.BATCH_SIZE_CONFIG, 16384) // Set batch size for sending messages in bulk
}Acknowledgment
Acknowledgment (or "acks") refers to the mechanism that ensures a producer’s message has been successfully received by the Kafka broker(s). When a producer sends a message, it can request different levels of acknowledgment, which affects the reliability of message delivery and the performance of the producer. Kafka provides three acknowledgment settings:
-
acks = 0 (No Acknowledgment)
-
Description: With acks = 0, the producer does not wait for any acknowledgment from the broker after sending a message. This means the producer will immediately consider the message as "sent" and continue sending the next messages without waiting for confirmation from the broker.
-
Reliability: Very low. There is a high risk of message loss because the producer won’t know if a message was received or if the broker went down before storing the message.
-
Performance: Very high. Since no acknowledgment is required, the producer can send messages quickly
-
-
acks = 1 (Leader Acknowledgment)
-
Description: With acks = 1, the producer will wait for an acknowledgment from the leader broker (the main broker responsible for the partition to which the message is sent) to confirm receipt. However, it does not wait for replicas (other brokers that hold copies of the partition) to acknowledge the message.
-
Reliability: Medium. This setting provides better reliability than acks = 0 because the leader broker must acknowledge receipt before the producer continues. However, if the leader broker crashes before the message is replicated, the message may still be lost.
-
Performance: Moderate. There is a slight delay as the producer waits for acknowledgment from the leader, but performance is still better than waiting for acknowledgment from all replicas.
-
-
acks = all (All Replicas Acknowledgment)
-
Description: With acks = all (or acks = -1), the producer waits for acknowledgment from the leader broker and all in-sync replicas (ISRs). The message is considered "committed" only when all replicas confirm receipt.
-
Reliability: Very high. This provides the highest level of reliability since the message is replicated to all in-sync replicas. Even if the leader broker crashes, another in-sync replica can take over without data loss.
-
Performance: Low compared to the other settings, as the producer must wait for acknowledgment from multiple brokers. This is slower but ensures data durability.
-
Retries
The retries configuration determines how many times the producer should attempt to resend a message if the initial sending fails. Network issues, temporary broker unavailability, or other transient issues can sometimes cause message delivery to fail. Setting retries allows the Kafka producer to automatically retry sending the message rather than immediately failing, which can significantly increase the reliability of message delivery.
When a producer tries to send a message and encounters a failure (e.g., a timeout, network issue, or broker error), it will retry the send operation up to the number of times specified by the retries configuration. However, Kafka’s producer retries only in cases where retrying might reasonably succeed, such as transient network issues or leader election in progress. If all retries fail, the producer will eventually throw an error.
To avoid overwhelming the Kafka broker with rapid retries, the producer can be configured with a delay between retries using the retry.backoff.ms setting. This delay defines the amount of time the producer waits between retry attempts.
Important Considerations with Retries:
-
Idempotence: Enabling acks=all with a high retry count may result in duplicate messages if retries are successful after a partial failure. To avoid this, Kafka supports idempotent producers. Setting
enable.idempotence=trueensures each message is sent only once, even after retries. -
Order Guarantee: Retrying can affect message ordering within a partition. If retries are enabled but
max.in.flight.requests.per.connectionis greater than 1, retries may cause out-of-order messages. Setmax.in.flight.requests.per.connection=1to maintain strict order if necessary. -
Max Retries: Setting retries to a high number can improve reliability but also increase the time the producer spends trying to send messages in case of persistent issues. Use it in conjunction with timeout settings to define limits on message attempts.
Batch Size
Batch size controls the maximum amount of data (in bytes) that the Kafka producer can batch together in a single request before sending it to the broker. Batching multiple messages together improves efficiency by reducing the number of requests to the Kafka broker, which in turn reduces network overhead and increases throughput.
When a producer sends messages to Kafka, it doesn’t necessarily send each message as soon as it is produced. Instead, Kafka groups multiple messages into batches, sending them together as a single request. This process reduces the number of network calls and increases efficiency. The batch.size configuration controls the maximum size of these batches.
-
If the Batch Size is Reached: If the accumulated messages reach the specified
batch.size(in bytes), the producer will immediately send the batch, even if there is more time remaining for other messages to join the batch. -
If the Batch Size is Not Reached: If the batch does not reach the maximum size, it will still be sent after a certain time delay, determined by the
linger.msconfiguration (the maximum time the producer will wait before sending an incomplete batch).
The batch.size setting is specified in bytes and is commonly set to something like 16384 bytes (16 KB) by default. The ideal batch size depends on your message sizes, throughput requirements, and network capabilities.
What is the reason for configuring the batch size?
-
A larger batch size can improve throughput by reducing the frequency of requests to the Kafka broker. Fewer requests mean less network overhead and higher message throughput.
-
A smaller batch size, combined with a low
linger.ms, results in messages being sent more frequently, which reduces latency but can increase the number of requests and reduce throughput. -
Sending larger batches can help to lower network costs because fewer packets are sent over the network.
Important Considerations:
-
Message Size: If your average message size is small, increasing the batch size can improve efficiency. But if messages are large, set
batch.sizeappropriately to avoid frequent partial batches. -
Memory Usage: Larger batch sizes require more memory in the producer, so setting a very high batch size may lead to increased memory consumption.
-
Latency Tuning with
linger.ms: To find the right balance between batching efficiency and latency, tune bothbatch.sizeandlinger.ms. linger.ms controls the delay in sending a batch to allow more messages to fill it, so smaller linger.ms means more frequent sends and lower latency, while a larger value helps in creating fuller batches.
Consumer
To consume messages from the Kafka cluster that I sent by the above producer examples, no additional dependency is necessary to add to the application.
The first step is to set up the consumer configuration, including details such as the broker address, deserialization format for keys and values, group ID, and automatic offset handling.
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.clients.consumer.KafkaConsumer
import org.apache.kafka.common.serialization.StringDeserializer
import java.util.Properties
fun createConsumer(): KafkaConsumer<String, String> {
val props = Properties().apply {
put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092")
put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer::class.java.name)
put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer::class.java.name)
put(ConsumerConfig.GROUP_ID_CONFIG, "kotlin-consumer-group")
put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
}
return KafkaConsumer(props)
}The first 3 properties are very similar to the producer configuration, so I omit further explanation. Just instead of serialization, the deserialization of key and value is configured.
The AUTO_OFFSET_RESET_CONFIG setting determines what a consumer should do when it starts reading a topic and finds no committed offset (i.e., it’s the consumer’s first time reading the topic or there’s no record of a previous offset for the consumer group).
This setting has two primary options, "earliest" and "latest", which influence where on the topic the consumer should begin reading messages. The AUTO_OFFSET_RESET_CONFIG configuration is useful for defining consumer behavior in cases like consumer restarts or consumer group membership changes.
-
earliest: If there’s no committed offset, the consumer will start reading from the beginning of the partition. This setting ensures the consumer doesn’t miss any messages, as it will read from the earliest offset available in the topic.
-
latest: If there’s no committed offset, the consumer will start reading from the latest offset (end of the partition). The consumer will ignore all past messages and only read new messages arriving after the consumer has started.
The GROUP_ID_CONFIG setting specifies the consumer group ID for a consumer. This group ID determines which consumer group the consumer belongs to, allowing Kafka to manage the consumer’s behavior and interactions with other consumers in the same group.
Purpose of GROUP_ID_CONFIG
-
Partition Assignment: Consumers within the same group will divide the topic’s partitions among themselves. Kafka ensures that each partition is consumed by only one consumer in the group at any time. This division allows multiple consumers to work in parallel within a group, balancing the load and increasing the processing speed.
-
Offset Tracking: The consumer group ID also determines the offset that each consumer reads from. Kafka tracks the last processed offset for each consumer group separately, so a consumer in a group will only read messages that haven’t been processed by others in the same group. This behavior makes consumer groups especially valuable for applications where each message needs to be processed only once within a group.
-
Rebalancing: When a consumer joins or leaves a consumer group, Kafka will rebalance the partitions among the active consumers in that group. This allows Kafka to dynamically handle changes in the number of consumers, ensuring high availability and efficiency.
Once the consumer is configured, I can subscribe it to one or more topics. The consumer will automatically rebalance if more consumers with the same group ID subscribe to the same topic.
fun subscribeToTopic(consumer: KafkaConsumer<String, String>, topic: String) {
consumer.subscribe(listOf(topic))
println("Subscribed to topic $topic")
}
suspend fun consumeMessages(consumerName: String, consumer: KafkaConsumer<String, String>) {
try {
while (true) {
val records = consumer.poll(Duration.ofMillis(100)) // Poll every 100 ms
for (record in records) {
println("$consumerName-Received message: key=${record.key()}, value=${record.value()}, partition=${record.partition()}, offset=${record.offset()}")
}
yield()
}
} catch (e: Exception) {
println("Failed to send message with error: ${e.message}")
}
}With the consumer subscribed to a topic, we can now poll for messages in a loop. Each call to poll() retrieves records from Kafka, which we can then process. I use a call to yield() after every poll to give the other consumer the chance to poll for messages.
In this example:
-
The consumer polls for messages every 100 milliseconds.
-
Each message record provides information like key, value, partition, and offset, which I print to the console.
Subscribed to topic my-third-topic
Received message: key=404c8978-5b7c-44f4-8303-fc12aafab0cf, value=producer1-message-1, partition=0, offset=0
Received message: key=ff1d9519-52fa-4349-993e-fdcb1b11fdfb, value=producer2-message-1, partition=0, offset=1
Received message: key=582b8f27-1fd0-4193-9c5f-08c79576a9f9, value=producer1-message-2, partition=0, offset=2
Received message: key=b00d7f9c-5a54-4ca9-bd34-423dfc038207, value=producer1-message-3, partition=0, offset=3
Received message: key=5a3fcbd1-e6b9-4ad3-87e4-1a3af27ad1f2, value=producer2-message-2, partition=0, offset=4
Received message: key=dfded616-1467-4a67-805b-b5101dacf680, value=producer1-message-4, partition=0, offset=5
Received message: key=b14485b0-c944-4711-a21a-97c755ee41a6, value=producer1-message-5, partition=0, offset=6
Received message: key=f34ddb78-78a7-44a4-8419-cf69030d14dc, value=producer2-message-3, partition=0, offset=7
Received message: key=71b26098-bfa8-402b-ae8c-0ef81654bcf7, value=producer2-message-4, partition=0, offset=8
Received message: key=2df277dc-630e-44fc-ab09-1491ce21fb80, value=producer1-message-6, partition=0, offset=9
Received message: key=3e38b9df-88ea-4660-bfda-cc3c9b73b23f, value=producer2-message-5, partition=0, offset=10
Received message: key=229b1f8f-f14d-4621-9903-220e74f32c55, value=producer1-message-7, partition=0, offset=11
Received message: key=c7dc52c2-4584-4a58-826c-7fae0739778f, value=producer2-message-6, partition=0, offset=12
Received message: key=00144114-b537-40e8-85c5-a47906e65977, value=producer1-message-8, partition=0, offset=13
Received message: key=0ff70892-7a12-46df-af42-020fba05d960, value=producer1-message-9, partition=0, offset=14
Received message: key=2015d487-2458-4228-b463-54dab30163f9, value=producer2-message-7, partition=0, offset=15
Received message: key=0c3e8ac5-1787-4d3f-b235-37ee8576ff08, value=producer2-message-8, partition=0, offset=16
Received message: key=94e2a1d0-30f0-4ffb-ab0e-88e135282e6b, value=producer2-message-9, partition=0, offset=17
Received message: key=1391a698-3bad-408c-9ab3-92d6dd5dbec7, value=producer1-message-10, partition=0, offset=18
Received message: key=e5bb9b30-f652-41b4-8a2d-78131d532172, value=producer2-message-10, partition=0, offset=19This consumes all previously by the producer sent messages on the specified topic. When starting the application again, no additional messages are consumed because the offset is already committed.
Offset Management
Kafka consumers use offsets to track the position within a partition. By default, Kafka can commit offsets automatically, but you may want more control with manual offset management.
-
Automatic Offset Commit: Kafka automatically commits offsets at a regular interval when
enable.auto.commitis set
put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true") // Automatically commit offsets
put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000") // Commit every 1000 ms-
Manual Offset Commit: To gain more control over when offsets are committed, I can set
enable.auto.committo false and use thecommitSync()orcommitAsync()methods to commit offsets manually.
suspend fun consumeMessages(consumerName: String, consumer: KafkaConsumer<String, String>) {
try {
while (true) {
val records = consumer.poll(Duration.ofMillis(100))
for (record in records) {
println("$consumerName-Received message: key=${record.key()}, value=${record.value()}, partition=${record.partition()}, offset=${record.offset()}")
}
createConsumer().commitAsync() // manually commit all records retrieved with the poll
yield()
}
} catch (e: Exception) {
println("Failed to send message with error: ${e.message}")
}
}In the next example, I will have a look at how multiple consumers are working with the same topic.
launch {
createConsumer().use { consumer1 ->
subscribeToTopic(consumer1, topic)
consumeMessages("consumer1", consumer1)
}
}
launch {
createConsumer().use { consumer2 ->
subscribeToTopic(consumer2, "my-third-topic")
consumeMessages("consumer2", consumer2)
}
}To be able to consume from the my-third-topic again, I need to reset the offset for the consumer group. This can easily be done by using the Kafka UI.
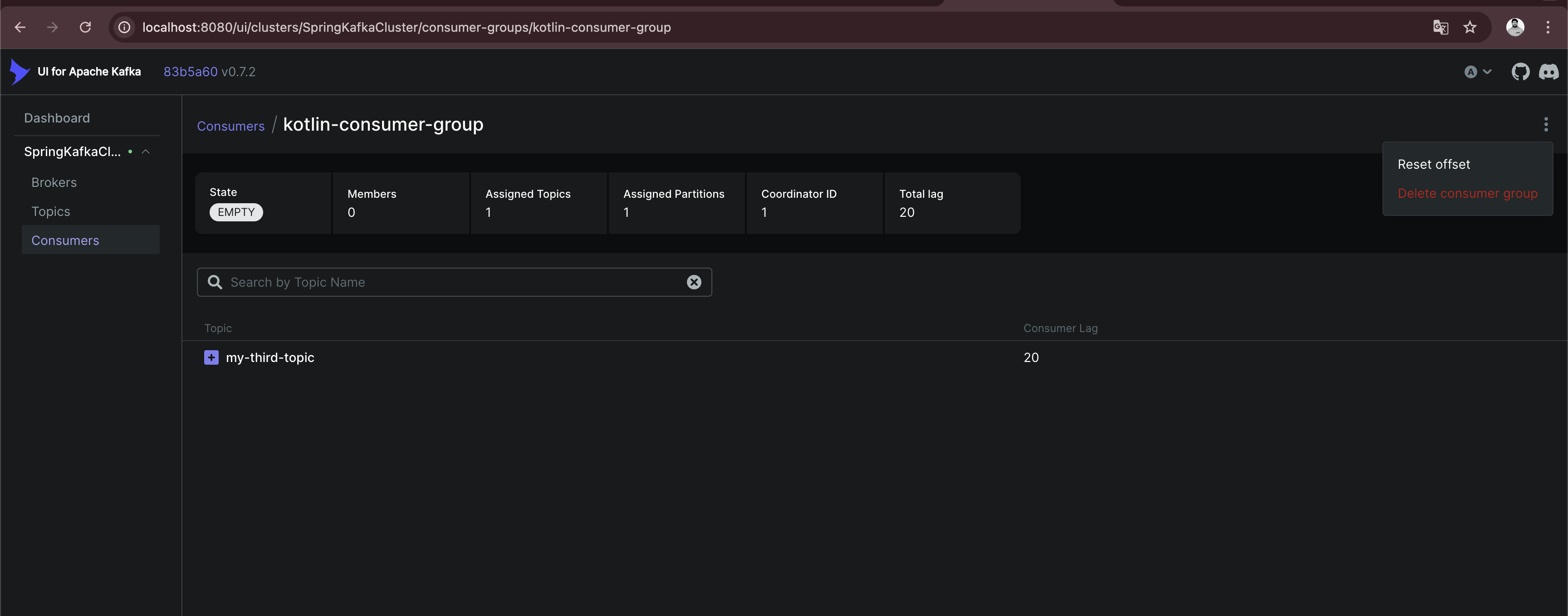
Subscribed to topic my-third-topic
Subscribed to topic my-third-topic
consumer1-Received message: key=3dd19188-d32b-460c-a835-e3166f4d58c1, value=producer2-message-1, partition=0, offset=105
consumer1-Received message: key=7169ca7e-eaf2-4335-b778-b05bdf3b3aaa, value=producer1-message-1, partition=0, offset=106
consumer1-Received message: key=159e1e22-9723-4c9a-8961-e098695994e4, value=producer2-message-2, partition=0, offset=107
consumer1-Received message: key=d80d0365-f98e-48b7-bffd-3e91f056de2c, value=producer1-message-2, partition=0, offset=108
consumer1-Received message: key=4eb21dae-479c-4d2e-9d04-15ca323332c2, value=producer1-message-3, partition=0, offset=109
consumer1-Received message: key=fed15377-529d-4229-8fb5-d84c42654861, value=producer1-message-4, partition=0, offset=110
consumer1-Received message: key=e6d08fd7-96ea-45ae-ab90-605d433e47c6, value=producer2-message-3, partition=0, offset=111
consumer1-Received message: key=66cc51bd-01c1-45c1-b071-b4d3911b660a, value=producer2-message-4, partition=0, offset=112
consumer1-Received message: key=10484497-a5ab-4f32-8b0b-be5b35e0e933, value=producer1-message-5, partition=0, offset=113
consumer1-Received message: key=8f740ecf-ab54-4ceb-8986-a5cecb132c08, value=producer2-message-5, partition=0, offset=114
consumer1-Received message: key=1384d84b-1995-4514-8edd-6d774ee502ad, value=producer1-message-6, partition=0, offset=115
consumer1-Received message: key=8897b5cc-e778-4c91-a64b-96c1930f309f, value=producer2-message-6, partition=0, offset=116
consumer1-Received message: key=9c43c964-b360-405c-804a-d5ecc741eb82, value=producer1-message-7, partition=0, offset=117
consumer1-Received message: key=d3067843-d91d-4107-af25-029449b7e6f7, value=producer2-message-7, partition=0, offset=118
consumer1-Received message: key=f6d047d5-2422-443a-be89-ecbb62d4d0c8, value=producer1-message-8, partition=0, offset=119
consumer1-Received message: key=7d2768dc-32da-407c-80b9-08aec4ebaab5, value=producer1-message-9, partition=0, offset=120
consumer1-Received message: key=23526f5b-1fec-4443-89ac-19a903fb9eed, value=producer1-message-10, partition=0, offset=121
consumer1-Received message: key=147766aa-00c0-4282-8735-2e0d0a06f52e, value=producer2-message-8, partition=0, offset=122
consumer1-Received message: key=2b9b34fd-69bd-4d66-872c-97693d5111d7, value=producer2-message-9, partition=0, offset=123
consumer1-Received message: key=4b06e20b-3c1b-4612-be9a-9744fba78564, value=producer2-message-10, partition=0, offset=124The result is some kind of disappointing because only one consumer is processing all the messages. So how can I distribute the messages between both consumers? As you remember there is a number of partitions for every topic set on creation. In the case of the my-third-topic topic it is 1 (because auto created on sending the first message). Only one consumer is allowed per partition. That means the second consumer is in waiting position until an additional partition is available or the first consumer goes down and Kafka automatically switches the consumer for the partition.
So to see the distribution of messages between the 2 consumers, I need to re-create the topic with more than one partition. Using the Kafka UI makes this very easy. Re-running the application is producing the below output:
Subscribed to topic my-third-topic
Subscribed to topic my-third-topic
consumer1-Received message: key=6bafd8e0-7f15-4185-ba71-0a6949a5179e, value=producer1-message-1, partition=0, offset=0
consumer1-Received message: key=5e9a46a2-4ae1-4760-934b-a95fa4c25f92, value=producer1-message-2, partition=0, offset=1
consumer1-Received message: key=11fabb33-2060-4e3f-a827-9dfbfe68a30d, value=producer2-message-2, partition=0, offset=2
consumer1-Received message: key=e9577b4c-3a9d-4c3b-a67f-3d52a52555b8, value=producer1-message-3, partition=0, offset=3
consumer1-Received message: key=aa38bde3-e15a-4ec4-b435-a0b19470b0e0, value=producer1-message-4, partition=0, offset=4
consumer1-Received message: key=489511ae-b958-4fe5-9446-190c53d4885f, value=producer2-message-3, partition=0, offset=5
consumer1-Received message: key=9e44e23a-5866-427d-80ad-cc6c21e11dbb, value=producer2-message-4, partition=0, offset=6
consumer1-Received message: key=8ff11559-fcbf-49cf-b9ce-e0599a6be7bb, value=producer1-message-6, partition=0, offset=7
consumer1-Received message: key=c73dfd8e-e4c8-4184-a794-fe7cdab461d0, value=producer1-message-7, partition=0, offset=8
consumer1-Received message: key=becdb887-4596-49a9-a483-7737a250ba66, value=producer2-message-7, partition=0, offset=9
consumer1-Received message: key=00341ecc-29fb-48b3-b169-40db8ac95888, value=producer2-message-8, partition=0, offset=10
consumer1-Received message: key=630540bc-f875-4848-b9f3-e800062f5fa1, value=producer2-message-9, partition=0, offset=11
consumer2-Received message: key=d46b647f-faad-404f-907c-6376d5b6f0d6, value=producer2-message-1, partition=1, offset=0
consumer2-Received message: key=8c7efae0-27c3-422b-a070-2fd8b4b67147, value=producer1-message-5, partition=1, offset=1
consumer2-Received message: key=8aae294b-e7c4-43dc-aad9-76ae8a5233b5, value=producer2-message-5, partition=1, offset=2
consumer2-Received message: key=5fd2316b-3a18-4f52-89f1-f80f07530836, value=producer2-message-6, partition=1, offset=3
consumer2-Received message: key=e7a31199-2103-4071-89ef-c149c000b704, value=producer1-message-8, partition=1, offset=4
consumer2-Received message: key=7ba305fd-a4ad-42a8-8b60-c8df21cd5263, value=producer1-message-9, partition=1, offset=5
consumer2-Received message: key=af1e7f98-4ebc-4909-bc86-5ad79b9d4136, value=producer2-message-10, partition=1, offset=6
consumer2-Received message: key=27d3431f-0b7e-40d3-a3ea-29fe2ded0a12, value=producer1-message-10, partition=1, offset=7The messages of partition 0 are consumed by consumer1 and the messages of partition 1 by consumer2. This can help to increase the performance for consuming messages.
Finally, I can combine the producer and the consumer examples.
fun main(): Unit = runBlocking {
val topic = "my-third-topic"
launch {
createProducer().use { producer1 ->
produceInfiniteMessages("producer1", producer1, topic)
producer1.close()
}
}
launch {
createProducer().use { producer2 ->
produceInfiniteMessages("producer2", producer2, topic)
producer2.close()
}
}
launch {
createConsumer().use { consumer1 ->
subscribeToTopic(consumer1, topic)
consumeMessages("consumer1", consumer1)
}
}
launch {
createConsumer().use { consumer2 ->
subscribeToTopic(consumer2, "my-third-topic")
consumeMessages("consumer2", consumer2)
}
}
}The produceInfiniteMessages - function creates messages in a while - loop, that are processed by both consumers.
Kotlin Kafka
If you want to use a more Kotlin idiomatic solution for writing code to connect to Kafka you can have a look on Kotlin Kafka of Simon Vergauwen. Because the examples in this post should only give an introduction to understand Kafka, I omitted this (also for the Java SDK more code examples are available to search for).
Conclusion
In today’s post, I introduced the essentials of Kafka, covering its core architecture and the fundamental components, including producers, consumers, brokers, and topics. I explored how Kafka’s distributed nature and partitioning model support scalability, and I touched on its message retention and fault tolerance mechanisms, which enable high-throughput, reliable messaging for real-time data processing.
Kafka may seem complex initially, but it isn’t necessarily more complicated than other messaging solutions like RabbitMQ or ActiveMQ. The difference lies in Kafka’s focus on high-throughput and durability for large-scale data streams. While RabbitMQ and ActiveMQ excel in low-latency messaging and more traditional messaging patterns, Kafka is designed for handling large, continuous data streams reliably. Once you understand its core concepts—topics, partitions, and the consumer group model—Kafka's architecture is quite intuitive and can even simplify things in high-demand, data-heavy environments.
Looking forward, I plan to cover also more advanced topics that can enhance the mastery of Kafka. I’ll talk about detailed configurations for producers and consumers, offering insights into tuning performance and reliability. Advanced partitioning strategies will be discussed to help optimize data distribution in high-traffic scenarios, along with best practices for managing offsets and retention policies. Additionally, I’ll provide guidance on configuring Kafka for fault tolerance through replication settings, a critical aspect for resilient production deployments. All this I will show as part of a SpringBoot application that uses the Kafka integration.
Comments